Abstract
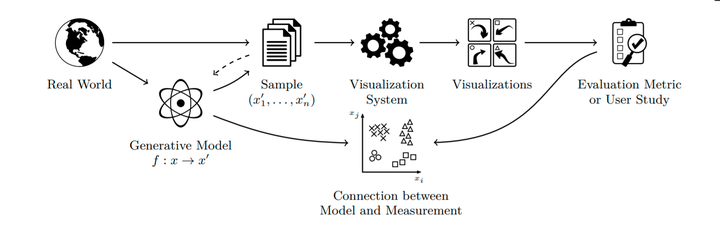
We argue that there is a need for substantially more research on the use of generative data models in the validation and evaluation of visualization techniques. For example, user studies will require the display of representative and uncon-founded visual stimuli, while algorithms will need functional coverage and assessable benchmarks. However, data is often collected in a semi-automatic fashion or entirely hand-picked, which obscures the view of generality, impairs availability, and potentially violates privacy. There are some sub-domains of visualization that use synthetic data in the sense of genera-tive data models, whereas others work with real-world-based data sets and simulations. Depending on the visualization domain, many generative data models are " side projects " as part of an ad-hoc validation of a techniques paper and thus neither reusable nor general-purpose. We review existing work on popular data collections and generative data models in visualization to discuss the opportunities and consequences for technique validation, evaluation, and experiment design. We distill handling and future directions, and discuss how we can engineer generative data models and how visualization research could benefit from more and better use of generative data models.