Representation problems in linguistic annotations: ambiguity, variation, uncertainty, error and bias
Abstract
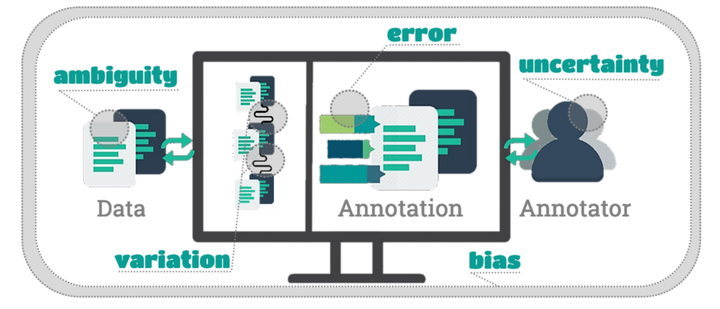
The development of linguistic corpora is fraught with various problems of annotation and representation. These constitute a very real challenge for the development and use of annotated corpora, but as yet not much literature exists on how to address the underlying problems. In this paper, we identify and discuss five sources of representation problems, which are independent though interrelated: ambiguity, variation, uncertainty, error and bias. We outline and characterize these sources, discussing how their improper treatment can have stark consequences for research outcomes. Finally, we discuss how an adequate treatment can inform corpus-related linguistic research, both computational and theoretical, improving the reliability of research results and NLP models, as well as informing the more general reproducibility issue.