Should We Trust (X)AI? Design Dimensions for Structured Experimental Evaluations
Abstract
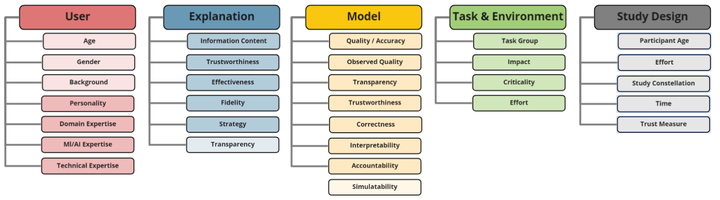
This paper systematically derives design dimensions for the structured evaluation of explainable artificial intelligence (XAI) approaches. These dimensions enable a descriptive characterization, facilitating comparisons between different study designs. They further structure the design space of XAI, converging towards a precise terminology required for a rigorous study of XAI. Our literature review differentiates between comparative studies and application papers, revealing methodological differences between the fields of machine learning, human-computer interaction, and visual analytics. Generally, each of these disciplines targets specific parts of the XAI process. Bridging the resulting gaps enables a holistic evaluation of XAI in real-world scenarios, as proposed by our conceptual model characterizing bias sources and trust-building. Furthermore, we identify and discuss the potential for future work based on observed research gaps that should lead to better coverage of the proposed model.