Abstract
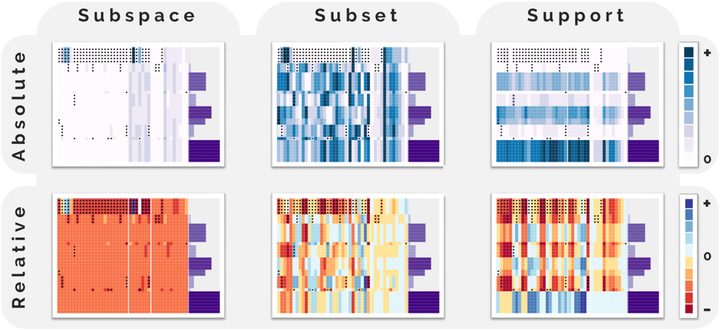
We present an approach that shows all relevant subspaces of categorical data condensed in a single picture. We model the categorical values of the attributes as co-occurrences with data partitions generated from structured data using pattern mining. We show that these co-occurrences are a-priori, allowing us to greatly reduce the search space, effectively generating the condensed picture where conventional approaches filter out several subspaces as these are deemed insignificant. The task of identifying interesting subspaces is common but difficult due to exponential search spaces and the curse of dimensionality. One application of such a task might be identifying a cohort of patients defined by attributes such as gender, age, and diabetes type that share a common patient history, which is modeled as event sequences. Filtering the data by these attributes is common but cumbersome and often does not allow a comparison of subspaces. We contribute a powerful multi-dimensional pattern exploration approach (MDPE-approach) agnostic to the structured data type that models multiple attributes and their characteristics as co-occurrences, allowing the user to identify and compare thousands of subspaces of interest in a single picture. In our MDPE-approach, we introduce two methods to dramatically reduce the search space, outputting only the boundaries of the search space in the form of two tables. We implement the MDPE-approach in an interactive visual interface (MDPE-vis) that provides a scalable, pixel-based visualization design allowing the identification, comparison, and sense-making of subspaces in structured data. Our case studies using a gold-standard dataset and external domain experts confirm our approach’s and implementation’s applicability. A third use case sheds light on the scalability of our approach and a user study with 15 participants underlines its usefulness and power.