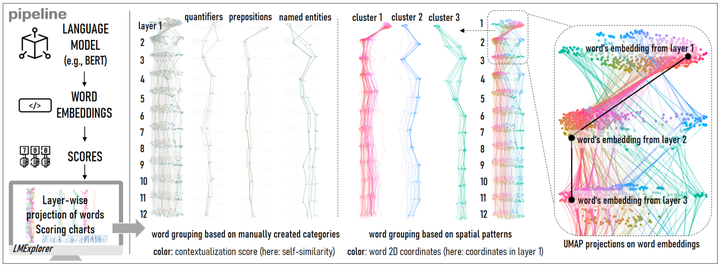
Abstract
Despite the success of contextualized language models on various NLP tasks, it is still unclear what these models really learn. In this paper, we contribute to the current efforts of explaining such models by exploring the continuum between function and content words with respect to contextualization in BERT, based on linguistically-informed insights. In particular, we utilize scoring and visual analytics techniques: we use an existing similarity-based score to measure contextualization and integrate it into a novel visual analytics technique, presenting the model’s layers simultaneously and highlighting intra-layer properties and inter-layer differences. We show that contextualization is neither driven by polysemy nor by pure context variation. We also provide insights on why BERT fails to model words in the middle of the functionality continuum.